学習率減衰/バッチサイズ増大とEarlyStoppingの併用で汎化性能を上げる@tensorflow2.0
この記事について
この記事では、以下2つを解説します。
- early stoppingと併用して学習率を適応的に変えていく手法をtensorflow2.xを使って実装する方法
- early stoppingと併用して、学習率の代わりにバッチサイズを適応的に変えて学習率減衰と同じ効果を得る手法の説明とtensorflow2.xその実装方法
学習率減衰とは?
学習率減衰(Learning rate decay)は深層学習の汎化性能向上のためによく使われる手法で、学習がある程度進んだ場所で学習率を下げる手法です。下図にあるように、学習率を落とすと、急激に精度が向上することが知られています。
では、いつ学習率を減衰させれば良いのでしょうか?2020年7月現在では、学習がある程度収束してから学習率を1/10~1/5程度に減衰させることが多いように思います。論文を見ていると、よく使われるCIFAR10やImageNetでは、ある程度挙動がわかっているので、減衰させるEpoch数を予め指定している場合もあります。

未知データでは、いつ学習率を減衰させるか?
では、未知データの場合はどうでしょうか?CIFAR10やImageNetのように挙動がある程度わかっている場合はepoch数で減衰箇所を指定出来ますが、実務で未知データを使って学習する場合は不可能です。
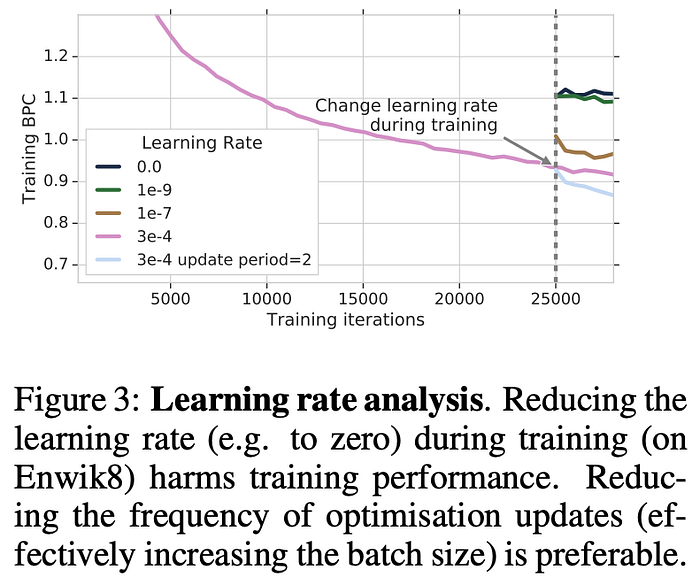
下図のようにデータセット、ネットワークの種類、最適化手法が変わると大きく挙動が変わります。実務において色々な実験条件を試す場合は、逐一それらの挙動を知った上で学習率減衰をかける必要がありますが、それを手動でやるのは現実的ではありません。
そのため、早期終了のようにある程度学習が収束したら、自動的に学習率を減衰させるような機構が必要になってきます。

Tensorflow2.xで早期終了+学習率減衰
tensorflow2.xでは、下記のようなtrain_step関数を使ったパラメータ更新が推奨されています。
この状態でoptimizerの学習率だけ下記のように変えようとすると、23行目でエラーが発生します。train_step関数の中のパラメータを変えると怒られるようです。
ですので、学習率を変えるときはtrain_step関数を再定義するようにします。下記のようにすれば、エラーださずに学習率を減衰させることができます。
早期終了と組み合わせた場合の学習のスクリプト全体は下記の通りです。学習が改善しないepoch数の許容回数を_max_patienceと定義し、それを超えると学習率減衰がかかるようになっています(58~65行目) 。コード全体はここを参照してください。
学習させた結果は下記の通りです。CIFAR10をVGG16で学習させており、最適化手法はSGD momentumを使っています。初期の学習率は0.001で、早期終了がかかる毎に学習率を1/4にする作業を2回行っています。
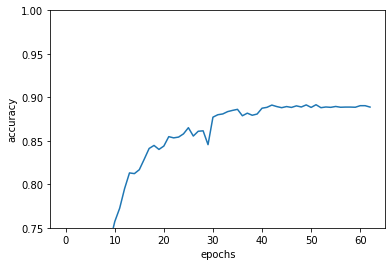
学習率の減衰は29,39epoch終了後に行われています。30epoch目の精度向上幅は大きいですが、40epoch目の減衰の効果はそれほど大きくありません。
学習率を減衰させる代わりにバッチサイズを増大させる
ところで、学習率を減衰させる代わりにバッチサイズを大きくしても同じ効果があります。この論文[2]によると、学習率を減衰させると精度が向上するのは更新のばらつきに相関があり、学習率を減衰させる代わりにバッチサイズを大きくしても同じスケールで更新のばらつきが減るから同じ効果が得られると主張しています。

また、Transformerの発展系であるCompressive Transformer[3]では学習率減衰は精度に悪影響で、バッチサイズ増大が精度向上に寄与したと報告しています。
実装としては、下記のようになります。60行目でtf.dataを用いたデータローダーのバッチサイズを変更しています。4行目でiterator作成をtrain_step作成時に再構成していることに注意してください。(なぜかわかりませんが、ここで再構成をしないとエラーが発生します)
結果は下記の通りです。適応的に学習率減衰/バッチサイズ増大の場所を変えているので、精度が急上昇するタイミングは異なりますが、学習率減衰と同じようにバッチサイズを増大させても精度が急上昇している箇所が存在するのがわかると思います。
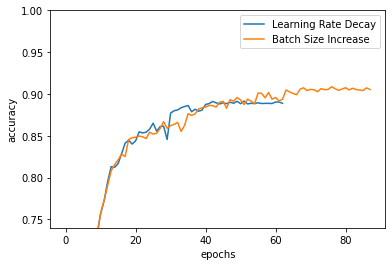
まとめ
このブログでは、学習率減衰とそれと同等の効果があるバッチサイズ増大の効果と実装方法を示しました。実務で色々なデータを扱っているとこのような適応的手法を使う必要がある場面に多々出くわします。そのような時に少しでも参考になれば幸いです。
Twitter , 一言論文紹介とかしてます。
Reference
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. Deep Residual Learning for Image Recognition. CVPR2016
- Samuel L. Smith, Pieter-Jan Kindermans, Chris Ying, Quoc V. Le. Don’t Decay the Learning Rate, Increase the Batch Size. ICRL2018
- Jack W. Rae, Anna Potapenko, Siddhant M. Jayakumar, Timothy P. Lillicrap. Compressive Transformers for Long-Range Sequence Modelling. ICLR2020
